Speech Enhancement with Sparse Coding in Learned Dictionaries
Christian Sigg, Tomas Dikk and Joachim M. Buhmann
This page provides complementary material for our ICASSP 2010 paper.
Enhanced Speech Examples
The following plots compare our dictionary learning based enhancer with multi-band spectral subtraction and a vector quantization based enhancer (see the paper for details of the algorithms). "Noisy mixture" is the log-magnitude spectrogram of the additive mixture of speech and interferer, and the three other plots show log-magnitude spectrograms after the mixture signal has been enhanced by the respective algorithm. Click on an image to play the example (8kHz WAVE format).
Street Noise at 6 dB SNR
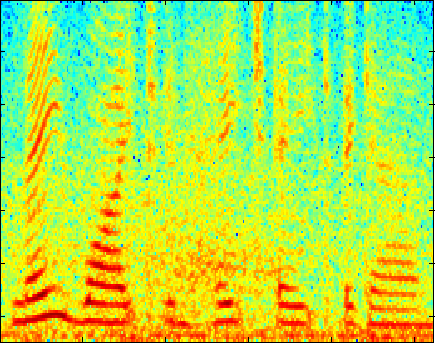

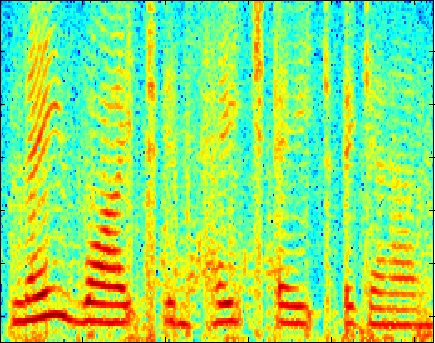
(speaker independent)

(speaker independent)
Music over Stereo in Closed Room at 0 dB SNR


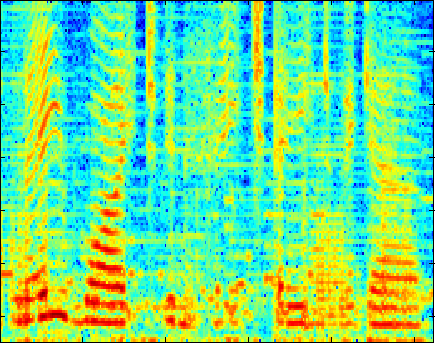
(speaker independent)
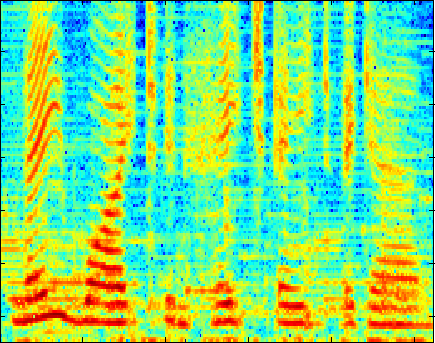
(speaker independent)
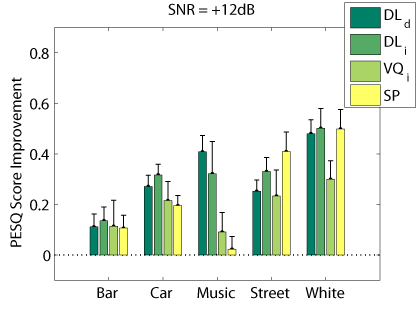
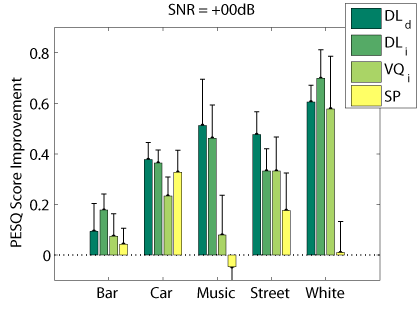
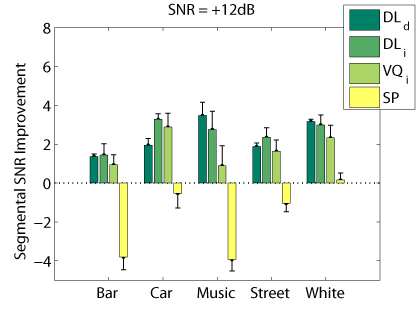
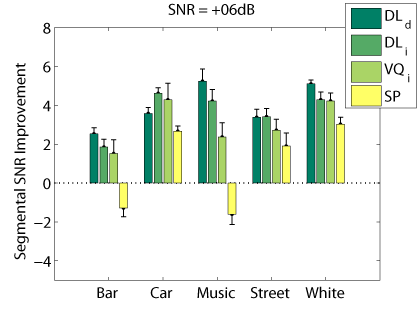
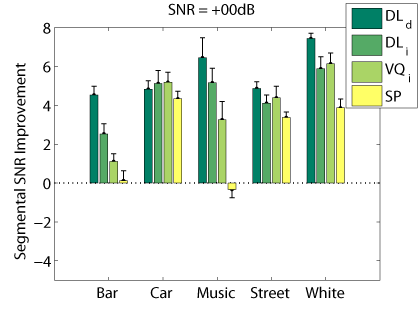
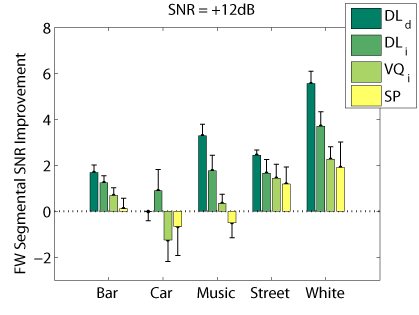
Objective Measures
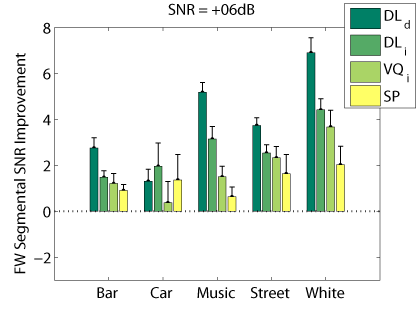
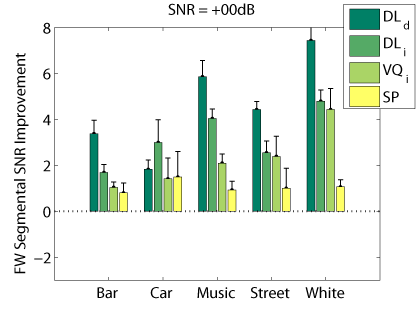
The following graphs compare our dictionary learning based enhancer (speaker dependent: DL_d, and speaker independen: DL_i) with multi-band spectral subtraction (SP) and vector quantization based enhancement (speaker independent: VQ_i), using several objective speech quality measures that have been shown to correlate with subjective speech quality judgement.
Cepstrum Distance
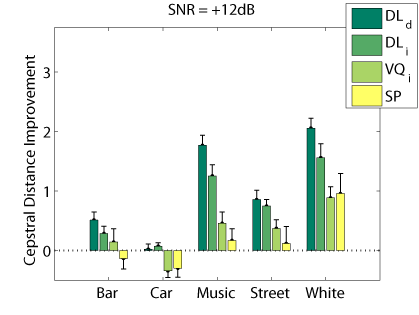

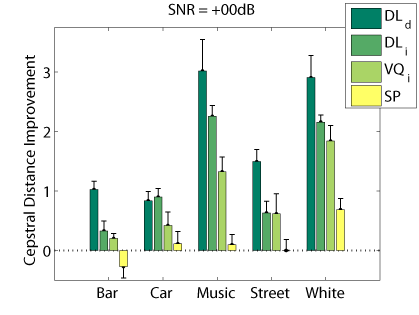
Segmental SNR
Frequency Weighted Segmental SNR
PESQ Measure